LLM Customization
LLM Customization: From General Intelligence to Specific Genius.
LLM Customization is the strategic process of adapting a generalized Large Language Model (LLM)—like GPT, Llama, or Claude—to a company’s unique domain, data, behavior, and security standards. Since off-the-shelf models lack specific internal knowledge, customization uses techniques like Retrieval-Augmented Generation (RAG) and Fine-Tuning to ground the model in proprietary information. This specialization drastically reduces “hallucinations,” ensures responses adhere to company policies and tone, and transforms a general AI tool into a reliable, enterprise-specific expert capable of automating complex, knowledge-intensive workflows.
Retrieval-Augmented Generation (RAG) Architecture
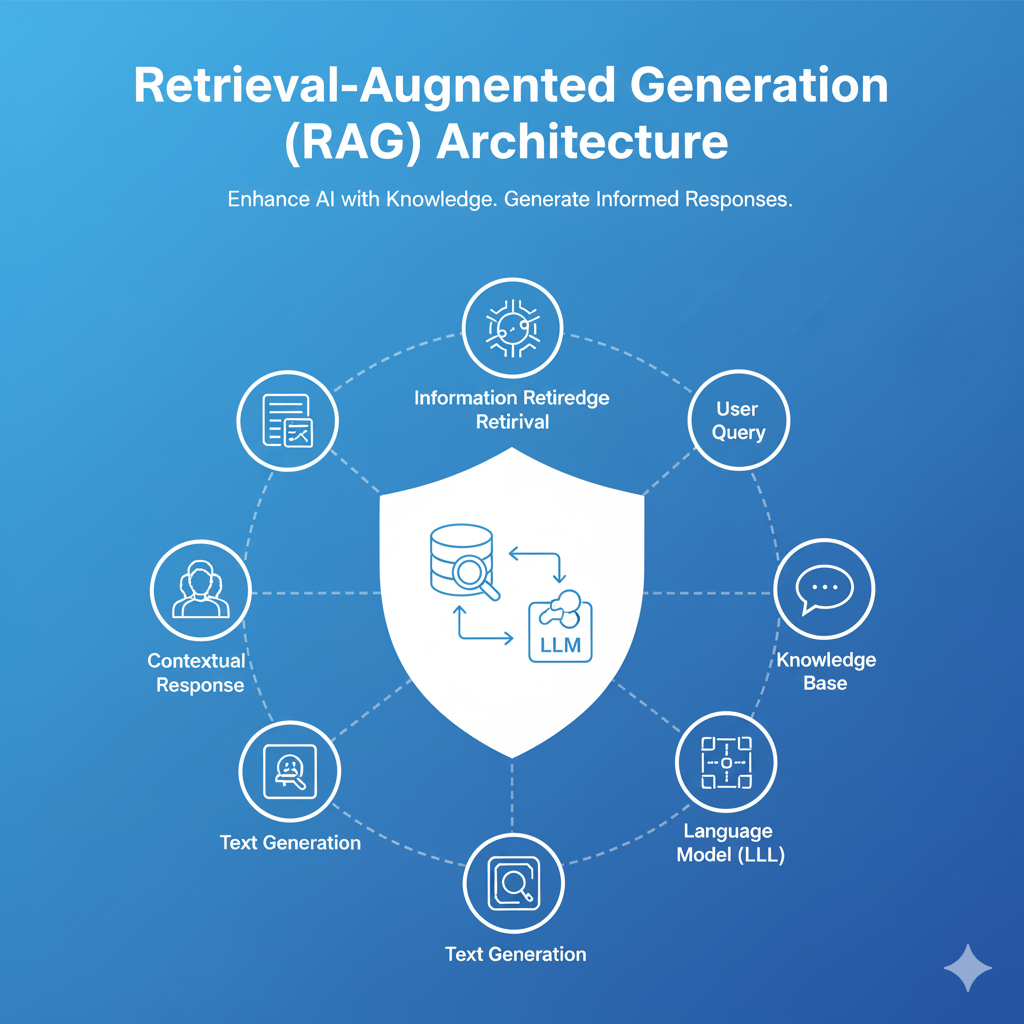
Retrieval-Augmented Generation (RAG) Architecture
Retrieval-Augmented Generation (RAG) Architecture is the system design framework that optimizes Large Language Models (LLMs) for enterprise use by providing them with dynamic, authoritative knowledge. The RAG pipeline separates the model’s general knowledge from a company’s specific, proprietary data. When a user asks a question, the architecture first retrieves the most relevant documents (Retrieval) from a secure, up-to-date vector database and then injects that factual context into the LLM’s prompt to generate a grounded, accurate response (Generation). This process is crucial for minimizing AI hallucinations, ensuring data privacy, and keeping AI applications current without the immense cost and effort of constant model retraining.
Our Services
- End-to-End RAG Pipeline Development We design and build the complete RAG workflow, including data ingestion, transformation, vector indexing, retrieval logic, and final prompt augmentation stages, ensuring fast and reliable factual grounding.
- Vector Database Selection and Implementation We consult on and implement the optimal vector database solution (e.g., Pinecone, Weaviate, Milvus, or integrated cloud vector search) tailored to your data volume, security needs, and required query latency.
- Document Pre-processing and Chunking Strategy We engineer advanced data pipelines to break down complex, unstructured documents (PDFs, contracts, internal wikis) into semantically coherent “chunks” and create high-quality vector embeddings for precise search relevance.
- Advanced Retrieval and Re-ranking Optimization We implement and tune sophisticated retrieval techniques like Hybrid Search (combining keyword and vector search) and Re-ranking models to ensure the most relevant information is consistently prioritized and fed to the LLM.
- Real-Time Data Sync and Knowledge Refreshing We establish automated, continuous ingestion pipelines that monitor source systems (CRMs, ERPs, live feeds) and update the vector index in near real-time, guaranteeing that the AI’s responses are based on the latest available enterprise data.
Model Fine-Tuning and Task Specialization
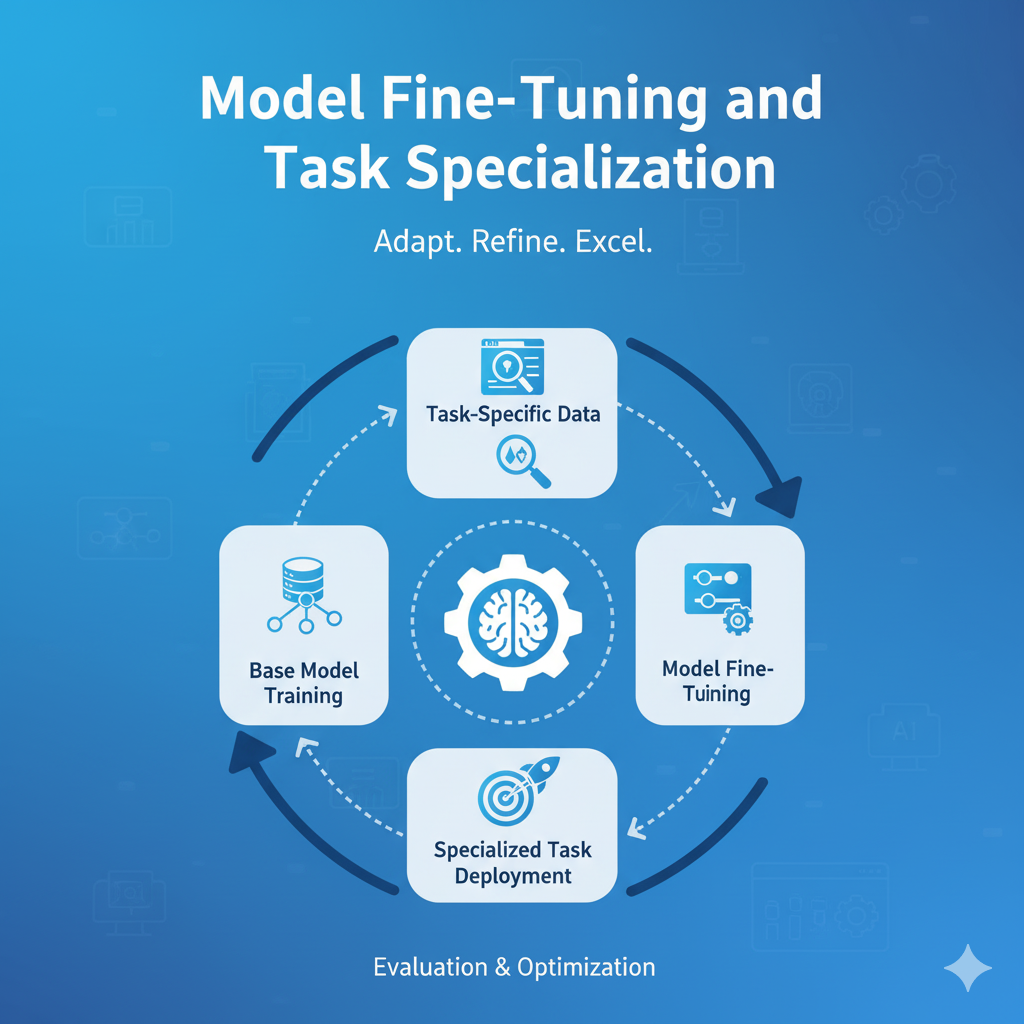
Model Fine-Tuning and Task Specialization
Model Fine-Tuning and Task Specialization is the targeted process of adapting a pre-trained Large Language Model (LLM) to consistently perform a specific business function or generate content in a unique style. Unlike RAG which adds external knowledge at query time, fine-tuning modifies the model’s internal parameters using a small, high-quality, labeled dataset. This technique is used to embed complex instructions, domain-specific terminology (jargon), and a desired tone/format directly into the model, resulting in superior performance for tasks like classification, sentiment analysis, code generation, and producing highly standardized, reliable, and compliant outputs.
Our Services
- Parameter-Efficient Fine-Tuning (PEFT) Implementation We utilize state-of-the-art PEFT methods, such as LoRA (Low-Rank Adaptation) or QLoRA, to specialize large models quickly and cost-effectively, drastically reducing computational memory and GPU requirements compared to full fine-tuning.
- Custom Dataset Curation and Annotation We collect, cleanse, and meticulously label proprietary training data to create a high-quality, task-specific dataset that effectively teaches the model the required format, style, and domain-specific vocabulary.
- Instruction Tuning for Behavior Alignment We apply instruction tuning to align the LLM’s general knowledge with your specific workflow requirements, ensuring it accurately follows complex, multi-step directions or policy constraints provided in a prompt.
- Domain and Tone Specialization We train the model to consistently adopt your brand’s unique voice, technical jargon, or required professional tone (e.g., legal, clinical, highly formal), making the AI output indistinguishable from an internal expert.
- Model Deployment and Post-Tuning Evaluation We manage the training infrastructure, deploy the lightweight fine-tuned adapters (LoRA weights), and perform rigorous A/B testing and quantitative evaluation to ensure the specialized model meets defined accuracy and consistency KPIs in production.
Proprietary Data Engineering for Grounding
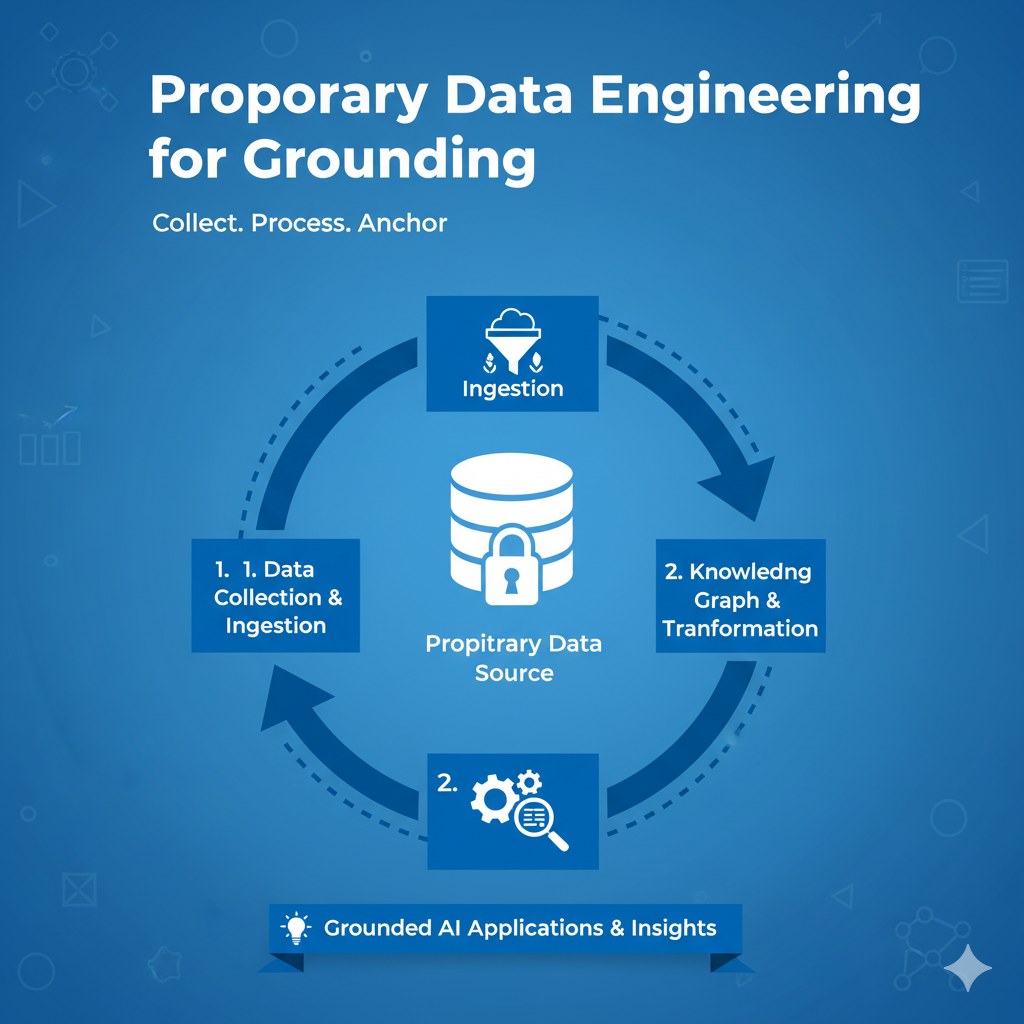
Proprietary Data Engineering for Grounding
Proprietary Data Engineering for Grounding is the foundational service that prepares a company’s internal, unstructured knowledge (documents, databases, codebases) to be accurately and securely used by a Retrieval-Augmented Generation (RAG) system. This involves transforming raw, diverse formats into high-quality, retrievable data assets. The service focuses heavily on defining and executing sophisticated chunking strategies, utilizing embedding models to convert text into searchable vectors, and building reliable data pipelines that ensure the RAG knowledge base is always current, relevant, and properly structured for semantic search.
Our Services
- Data Ingestion Pipeline Development (ETL/ELT) We build and automate scalable data pipelines that securely extract, clean, and load data from diverse proprietary sources—including SharePoint, CRMs, internal APIs, and data lakes—into an AI-ready environment for indexing.
- Advanced Chunking Strategy Design We define and implement optimal chunking methods (e.g., recursive, semantic, or hierarchical chunking) based on the structure and content of your documents to ensure maximum contextual integrity and retrieval precision at query time.
- Embedding Model Selection and Vectorization We select the most effective text-to-vector embedding model for your domain, generate high-quality vector embeddings for all data chunks, and manage the vectorization process at scale.
- Metadata Enrichment and Filtering We enrich data chunks with relevant metadata (e.g., source, author, date, user access permissions) during the ingestion process, enabling advanced filtering and role-based access control (RBAC) during retrieval for enhanced security and relevance.
- Data Freshness and Index Maintenance We establish automated mechanisms to monitor the freshness of source data, managing the update and re-indexing schedules for the vector store (persistence) to ensure the RAG system always operates with the latest, most accurate information.
Prompt Engineering and Template Optimization
Prompt Engineering and Template Optimization
Prompt Engineering and Template Optimization is the strategic service of creating, refining, and standardizing the text inputs given to Large Language Models (LLMs) to consistently elicit high-quality, structured, and relevant outputs. It is the art of “programming” the AI with words, transforming vague requests into highly specific instructions. By developing reusable prompt templates and leveraging advanced techniques, we ensure the LLM’s responses align with precise business needs, reducing variability and maximizing the AI’s efficiency and reliability in production.
Our Services
- Advanced Prompt Strategy and Design We craft high-impact prompts that use techniques like Role Specification (“Act as a senior legal analyst…”) and Zero-Shot CoT (Chain-of-Thought) to unlock deeper reasoning and direct the LLM toward complex, multi-step problem-solving.
- Few-Shot and Exemplar Training We develop Few-Shot Prompt Templates by providing the model with a small number of curated input-output examples, enabling it to learn the desired tone, structure (e.g., JSON or bulleted lists), and specific formatting required for a task.
- System Prompt and Guardrail Integration We design persistent System Prompts that define the AI’s core identity, security rules, and response constraints, effectively creating a behavioral guardrail that minimizes risks like hallucination, bias, or non-compliant output.
- Template Optimization and Version Control We create a library of production-ready, version-controlled prompt templates that are optimized for minimal token usage (cost-efficiency) and integrate seamlessly into your application logic and CI/CD pipelines.
- Iterative Testing and Metric Tracking We conduct systematic testing and iterative refinement of prompts using human evaluation and automated metrics to ensure high accuracy, consistency, and alignment with business KPIs before deployment.
Hybrid LLM Strategy and Tool Selection
Hybrid LLM Strategy and Tool Selection
Hybrid LLM Strategy and Tool Selection is the advisory service that helps companies choose, combine, and deploy the optimal mix of LLM customization techniques and hosting models for maximum business impact. Recognizing that no single model or method is a “silver bullet,” this service creates a bespoke architecture that often blends fine-tuning (for specialized style and task mastery) with Retrieval-Augmented Generation (RAG) (for real-time, factually grounded answers). We then select the best combination of open-source models, proprietary cloud APIs (e.g., GPT, Claude, Gemini), and supporting orchestration tools (LangChain, LlamaIndex, vector databases) to optimize for accuracy, cost, latency, and compliance.
Our Services
- AI Use Case and Technique Mapping We analyze your prioritized AI use cases (e.g., customer support vs. legal analysis) to determine whether they require Factual Grounding (RAG), Behavioral Alignment (Fine-Tuning), or a Hybrid approach, ensuring investment is perfectly matched to the required outcome.
- LLM Benchmarking and Selection We conduct rigorous, real-world benchmarking across leading proprietary (OpenAI, Anthropic, Google) and open-source (Llama, Mistral) LLMs to recommend the model that offers the best balance of performance, token cost, and latency for your specific workload.
- Hybrid Architecture Design We design intelligent routing layers that dynamically switch between models—using a smaller, fine-tuned model for fast, internal tasks and a large, RAG-augmented model for complex, data-intensive queries—to optimize both cost and speed.
- Toolchain Integration for Hybrid Flows We recommend and integrate the necessary AI orchestration frameworks and tooling (e.g., LangChain for logic, vector databases for RAG, LoRA for fine-tuning) to manage the complexity of running multiple models and systems coherently.
- Governance and Deployment Model Consulting We advise on the most secure and compliant deployment model: Public API (for flexibility), Self-Hosted (for data sovereignty), or Hybrid (for balancing control over sensitive data with access to cutting-edge models).