MLOps (Machine Learning Operations)
MLOps: From Lab to Live, Instantly
MLOps is a set of practices that automates and manages the deployment, monitoring, and governance of machine learning models in production. It bridges the gap between data science, IT operations, and engineering, ensuring that models are built, trained, and deployed reliably and efficiently. By establishing repeatable, scalable pipelines, MLOps helps organizations continuously integrate new data, retrain models, and update predictions to maintain high accuracy and performance over time. This systematic approach reduces time-to-market for new models, minimizes operational risk, and enables rapid iteration, ultimately driving greater business value from AI investments.
ML Model Deployment and Infrastructure Setup
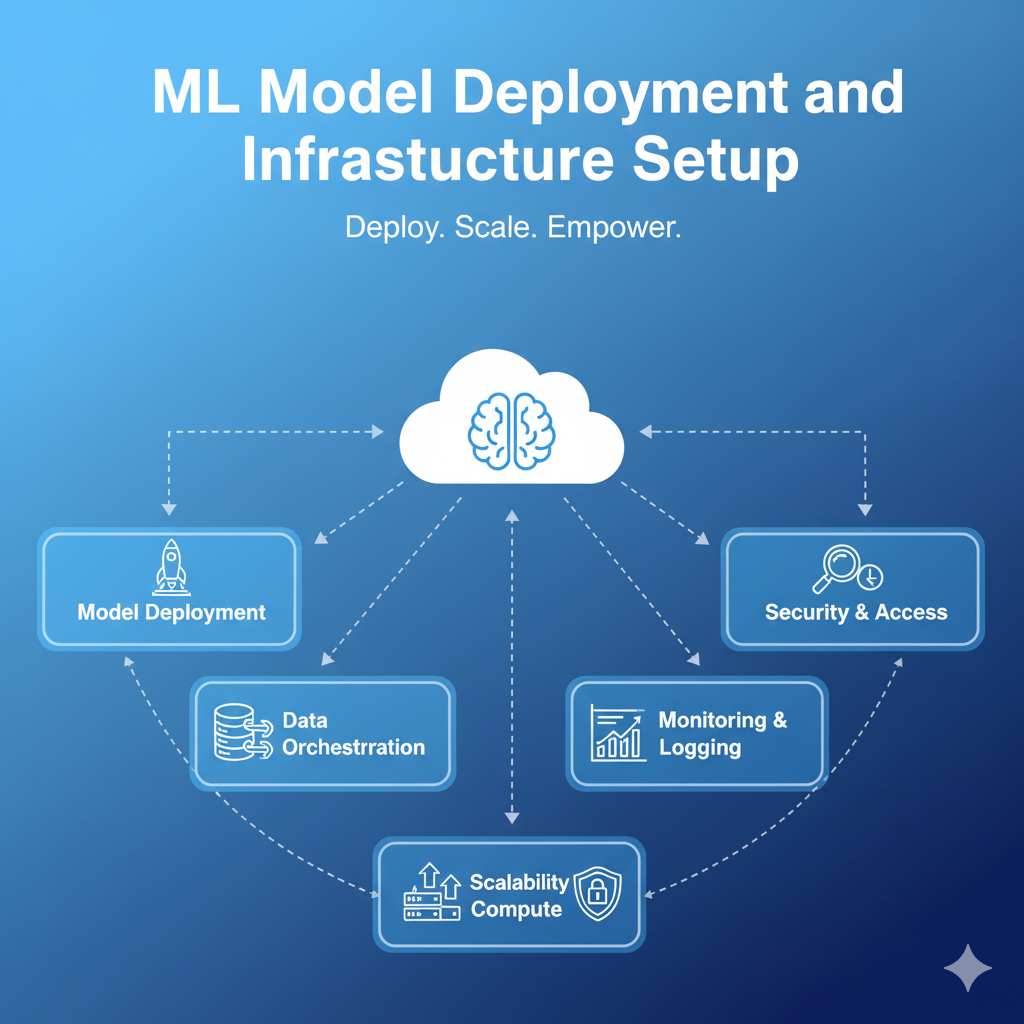
ML Model Deployment and Infrastructure Setup
ML Model Deployment and Infrastructure Setup is the critical process of transforming a trained machine learning model from a development environment into a production system where it can deliver real-time or batch predictions to end-users and applications. This service focuses on building the scalable, reliable, and secure infrastructure necessary to host and serve the model effectively. It includes selecting the right cloud environment, containerizing the model, configuring API endpoints, implementing load balancing for high throughput, and integrating the prediction service seamlessly into the client’s existing application ecosystem. A robust setup ensures minimal latency, high availability, and efficient resource scaling, maximizing the return on investment from the model development phase.
Our Services
- Cloud Architecture Design (AWS, Azure, GCP) We design and deploy a tailor-made cloud infrastructure specifically optimized for ML workloads, including selection and configuration of compute resources (GPUs/CPUs), serverless functions, and managed services.
- Model Containerization (Docker and Kubernetes) We containerize your trained models using Docker and orchestrate deployment via Kubernetes (K8s) or managed services like Amazon EKS, Google GKE, or Azure AKS for optimal scalability and portability.
- API Development and Endpoint Creation We build high-performance, secure REST or gRPC APIs for your model, enabling easy integration with client applications and ensuring low-latency real-time inference.
- Security and Access Control We implement robust security measures, including network segmentation, authentication, authorization, and data encryption, to protect your models and sensitive data in production.
- Inference Pipeline Optimization We optimize the model serving pipeline for cost and performance, utilizing techniques like model compression, auto-scaling rules, and specialized hardware accelerators.
Automated CI/CD for ML

Automated CI/CD for ML
Automated CI/CD for ML is the engineering discipline that applies the principles of Continuous Integration and Continuous Delivery specifically to machine learning workflows. It involves creating automated pipelines that handle the entire ML lifecycle—from code changes and data validation to model training, testing, versioning, and secure production deployment. This service ensures that every change (code, data, or configuration) triggers a complete, repeatable process, significantly reducing manual errors, accelerating the model release cycle, and maintaining the quality and reliability of models in production. By integrating testing and governance checks throughout the process, it enables rapid, safe iteration and continuous business value delivery from AI assets.
Our Services
- Pipeline Design and Implementation We design and implement end-to-end automated pipelines using tools like Jenkins, GitLab CI, GitHub Actions, or cloud-native solutions (e.g., Azure DevOps, AWS CodePipeline) tailored for ML workflows.
- Data and Code Validation Gates We incorporate automated testing gates for data schema validation, feature quality checks, and code unit/integration tests before model training commences.
- Model Training and Retraining Automation We configure triggers and schedules for automatic model retraining based on new data availability, performance degradation, or scheduled maintenance windows.
- Model Testing and Quality Assurance We implement advanced model testing, including performance comparison against baselines, robustness checks, and bias detection, ensuring only validated models proceed to deployment.
- Rolling Deployments and Canary Releases We set up deployment strategies such as A/B testing, blue/green deployments, and canary releases to safely roll out new model versions to production with minimal risk and seamless rollback capabilities.
Model Monitoring and Performance Tracking
Model Monitoring and Performance Tracking
Model Monitoring and Performance Tracking is the continuous, real-time observation of machine learning models deployed in a production environment to ensure they remain accurate, reliable, and fair over time. This crucial service goes beyond simple infrastructure health checks by actively tracking key ML-specific metrics, such as data drift (changes in input data distribution), concept drift (changes in the relationship between input and output variables), and model accuracy degradation. By setting up automated alerts and dashboards, organizations can quickly detect when a model’s performance begins to slip, diagnose the root cause, and trigger a necessary retraining or investigation. This proactive approach minimizes financial loss, maintains customer trust, and maximizes the long-term utility of the deployed AI system.
Our Services
- Real-Time Performance Dashboarding We implement custom dashboards using tools like Grafana, Prometheus, or cloud-native monitoring services to visualize key metrics, including prediction latency, throughput, and business outcomes.
- Data Drift and Schema Drift Detection We set up automated pipelines to compare production data distributions against training data and alert the team when significant deviations (data drift or schema changes) are detected that could impact model quality.
- Concept Drift Identification We employ statistical techniques and tooling to monitor the true relationship between features and the target variable, alerting stakeholders when the model’s underlying assumptions are no longer valid (concept drift).
- Model Quality and Accuracy Tracking We track core model quality metrics (e.g., AUC, F1-Score, RMSE) using ground-truth data whenever available, and set up performance degradation thresholds to automatically flag poor-performing models.
- Bias and Fairness Monitoring We establish ongoing checks for model bias and fairness across different sensitive demographics or segments, ensuring the model’s decisions remain equitable and compliant with ethical standards.
Data and Model Versioning

Data and Model Versioning
Data and Model Versioning is the critical practice of tracking and managing every component involved in the machine learning lifecycle: the datasets, the model code, the training configuration, and the resulting trained model artifacts. This systematic approach ensures reproducibility, auditability, and governance. By versioning data and models, organizations can accurately pinpoint which data set was used to train a specific model version deployed in production, making it easy to roll back to a known working state, comply with regulatory requirements, and debug performance issues. It transforms the often chaotic nature of ML experimentation into a standardized, traceable engineering process.
Our Services
- Integrated Version Control Setup We implement tools like DVC (Data Version Control) and Git-based systems to connect code, data, and models, establishing a single source of truth for all ML artifacts.
- Model Artifact Management We configure a centralized Model Registry to store, tag, and manage different model versions, performance metrics, and metadata, ensuring a clear history of every deployable artifact.
- Data Snapshotting and Provenance We establish automated processes for creating immutable, timestamped snapshots of training, validation, and testing datasets, ensuring data provenance and historical integrity.
- Experiment Tracking and Metadata Logging We deploy platforms like MLflow or specialized cloud services to log and track every experiment run, recording hyperparameter choices, environment details, and performance metrics associated with each model version.
- Regulatory Compliance and Audit Trails We build comprehensive audit trails linking predictions to the exact model and data version used, fulfilling compliance requirements for sectors like finance, healthcare, and insurance.
Bias and Explainability (XAI) Implementation
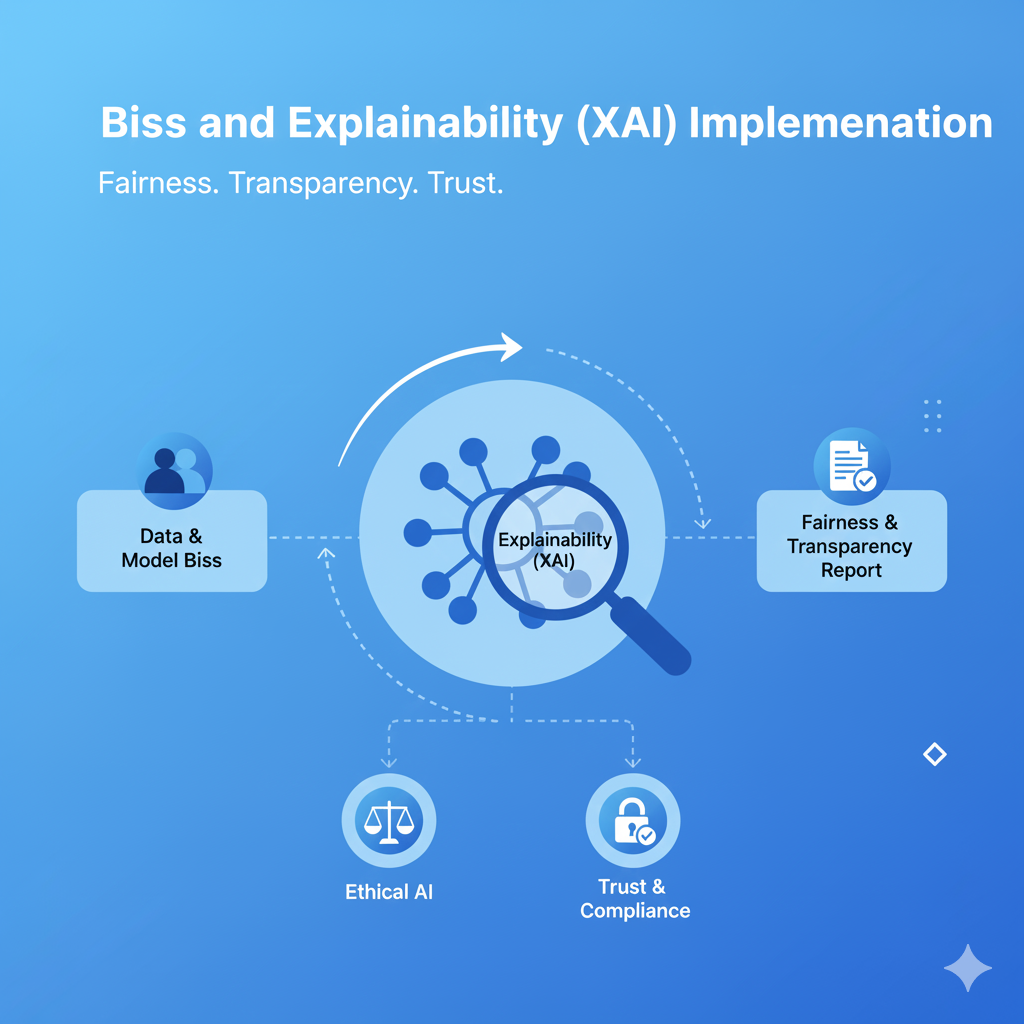
Bias and Explainability (XAI) Implementation
Bias and Explainability (XAI) Implementation is a crucial set of services focused on ensuring that deployed machine learning models are fair, transparent, and trustworthy. Bias mitigation aims to detect and correct systemic prejudices embedded in data or algorithms that lead to unfair outcomes for specific demographic groups. Explainability (XAI) provides tools and techniques to interpret a model’s complex decisions, allowing human users to understand why a particular prediction was made. This implementation is essential not only for ethical reasons and maintaining user trust but also for regulatory compliance (e.g., GDPR, sector-specific mandates) and effective debugging, transforming opaque “black-box” models into transparent, governable assets.
Our Services
- Bias Detection and Fairness Audits We conduct comprehensive audits using established metrics (e.g., disparate impact, equal opportunity difference) to detect hidden biases in training data and model predictions across sensitive attributes.
- Model Agnostic Explainability Integration We implement state-of-the-art explainability techniques like LIME (Local Interpretable Model-agnostic Explanations) and SHAP (SHapley Additive exPlanations) to provide local (per-prediction) and global model interpretations.
- Bias Mitigation Strategy Development We develop and apply pre-processing, in-processing, and post-processing techniques (e.g., re-weighting, adversarial debiasing) to reduce and mitigate identified sources of model bias.
- Explainability Dashboard and Interface Development We build interactive dashboards and user interfaces that present model explanations to stakeholders—data scientists for debugging, business users for decision support, and auditors for compliance checks.
- Regulatory Compliance and Reporting We help establish governance frameworks and automatic reporting features that document fairness metrics and model rationales, ensuring adherence to increasingly stringent AI regulatory requirements.